【DBflute】PostgreSQL11以降でProcedurePmbが生成できない問題【解決】
モイ!お久しぶりです。PaZooです。
皆さんお元気ですか。私はついさっきまでくたばってました。。。
何故くたばってたかって??それは表題の通りです。
それでは早速お話していきましょう。
事の発端
むかーしむかし、あるところにテスト用DBを構築したそうな。
で、突っ込んだDBはPostgreSQL12でした。
そして、作ったSP(function)はreturns table記法です。
以前6ヶ月前くらいに一度DBfluteを実行していて、成功していた実績がありました…
が!!!!!今流してみると。。
すっとこどっこいProcedurePmbが生成されないじゃない!!!何故?!!!
ひじょーーーーーーに焦りました。。
そりゃだって現場で「嘘つき」って言われるじゃん!!!
(いたもん…トトロいたもん…の気持ちでした。。)
枕を濡らして眠った夜。神様が現れて秒速解決。
現場から「どうなってんの!調べて!!」と言われ、早3日。
悔しい思いと、トトロいたもん…の気持ちを持ち合わせたぐしゃぐしゃな私。
真っ暗な部屋で一人。青い鳥で一言。
「助けてクレメンス…」
その声は某青いロボットに頼る某少年のように、製作者様へとたどり着いたらしく。。
なんとお声掛けいただきました…!!そして風のように秒速で解決。。
どうやら原因は、JDBCのバージョン(42.2.11以降)によるものらしい。
解決策は、JDBCのバージョンダウン(42.2.10)を行うこと。
具体的には、PostgreSQL11以降に現れた「ストアドプロシージャ」によってgetProcedures()はストアドプロシージャ専用のものとなったためfunctionでは取得できなかったことが背景のようです。
DBfluteはJDBCを同梱してくださっている親切設計なのですが、JDBCのバージョンを変更したい場合は、DBFluteクライアントの extlib ディレクトリ にJDBCのバージョン(42.2.10)を配置してあげると実行JDBCを変更してくれます。
セットアップについては公式サイトをご覧ください!
dbflute.seasar.org
「extlibフォルダなんてないよ!!」
…なければ作ればいいじゃない!!!extlibフォルダを新しく作って、JDBCを配置してあげてください!
実行Pathをどこかのファイルに定義する必要はなく、自動で切り替えてくれます。
また、切り分けとしてストアドファンクションの構成が問題なのか調べてみました。
新しいJDBCのバージョン(42.2.11以降)では、カーソルでやってみたり色々検証しましたが、returns table記法に限らずfunctionはすべて取得できませんでした…。
「じゃあとにかく古いJDBCを指定すればええやん?!」というわけでもなく。古すぎるJDBCだと「認証型うんちゃら~サポートしてないよ!」というエラーが出ます。
これらの検証結果があり、今回は42.2.10を指定しています。
DBfluteユーザーの皆様でPostgreSQL11以降を導入する(若しくは検討している)方、バージョンアップを検討している方へ…ぜひブログ記事を見てくれ…届いてくれ…!
ちなみに、公式サイトにて今回の事象についての回避策を記載していただけるとのことでした!
また、今後はどちらもサポートしていけるように検討していただけるみたいです。
製作者様、神!!!!!
まとめ
私と同じ事象が発生した方は、解決策として挙げている内容をぜひ検証してみてください!
それと、製作者様とコンタクトできたのはみんな大好き青い鳥(Twitter)でお声掛けいただきました。
MLやSlackへの参加も行っていましたが、コミュ力ブロンズな私。
「製作者様にお声掛けするタイミングってなかなか難しいぞ…」と思い、青い鳥でつぶやいたことが今回のターニングポイントだったのかもしれません。
DBfluteで困ったときはつぶやいてみると、もしかしたらあなたの前にも神様が現れるかもしれません…!
製作者様、本当にありがとうございました!!!
twitter.com
ちょっくらコンビニ(社内イベント登壇)に行ってきた話。
皆さんこんにちは。管理人のPaZooです。
今回お話するのは、『社内イベントに登壇してきた』という内容です。
実はこのイベント、今回AdventCalendarの記事に取り上げられているイベントでして当記事では参加者から見たイベントへの熱意が楽しめる記事となっています。
企画者から見たイベントへの想いが綴られた記事は以下のリンクからどうぞ!
それでは、早速書いていきます。
プロローグ
ある日のこと。
「あーーーどうにか人前で話して緊張しない強いメンタルがほしいーーー」
ここぞとばかりにサンタさんにお願いしていたのですが、こればっかりはどうにもこうにもいかないものだったらしく私の言葉は空しく空を切ることに。
ここ最近を振り返ってみると、人前に立って話すきっかけが多くそのたびに緊張しまくってヘタこいていました。
そんなある日のこと。神様はどうやら空から見ているらしく。
『PaZooさん、社内イベントに出てみない??』
まるで「今からコンビニ行かねえ?」のレベルで軽ーくある人からお誘いを受けました。
ここでいう”社内イベント”というのは、自社内にいるすべての技術者が集まって技術的な話をするイベントのことです。
うちの会社は、SESと呼ばれる業界にいるため社外で働いている人もいれば社内で働いている人もいます。
そのため、あまり他の技術者と交流することができず結果的に現場に出ている人は割と孤独を感じる日々を送りがち。私も例に漏れずそのひとりです。
うーーーーーーん、行く。一緒にハーゲン〇ッツ買いに行こ。
誘われたことをうれしく思い、にんまりしながら、まるでコンビニに行くかのようにあっさりと社内イベントへ参加することを決めました。
ここで、事件は起きる。
「参加しまっす!」と意気込んだのは良いものの、何を題材に話そうか。
結局話すネタは現場で行っている話を簡素化して、世間的に通ずる「小ネタ」みたいな仕事の進め方について取り上げることにしました。これでネタはまあいいだろう。
ここでふと考えたことが頭をよぎり、ぴたっと動きが止まりました。
「そういえば、今回の社内イベントってどのくらいの人の前で話すんだろう…」
そうなのです、完全に墓穴なのです。
うちの会社、かなりの規模で人が所属しておりひじょーーーーーーに人が多い。そんな中に私のようなお豆腐メンタルな人間が出る幕はなかったのです。
大人数の前で、魅せるプレゼンをしたことがない。というかそんなに人前で話すことに慣れていない私にとって、誘いを受けた後の祭りだったのです。
そして僕にできること
少人数グループだとある程度主導権を持って話すことができる。だけど、人に魅せるプレゼンなんてしたことない。
そんな私が行きついたのは、「ひたすらに前を向いて経験を積むこと」でした。
具体的にいうと、練習のためにビデオやボイスメモを取って自分のプレゼンを見返したり、プレゼン資料の展開スピードに合ったトークが出来ているかチェックしたり。
在宅勤務というのもあり、仕事が終わったらすぐに資料の見直しに入ったりビデオ録画でプレゼン練習をしたり本番までひたすらに練習を重ねました。
資料の作成については、直属の上司に相談してとにかく分かりやすい資料にすることを心掛けました。資料の作成も経験値がものを言います。
いい資料とは何なのか。毎日考えて消して修正して…の繰り返しでした。
そして僕ができたこと
本番当日。もちろん非常に緊張していました。
練習したとはいえ、やはり色んな人の前で発表するというのは経験にないものです。
頭が真っ白になりながらも、その日は何とかプレゼンを終え、帰宅。(めちゃくちゃ家にいるんですけどね。)
後日のアンケート回答を見ると「5W1Hの大切さ」や「分析やヒアリングしながら行動し、しっかり振り返りをすることの流れ」などプレゼンを通して伝えたかった内容がきちんと伝えることができたようで、嬉しいお言葉を頂くことが出来ました。
うん、やっぱりうれしい。自分の考えを誰かに伝えて、分かってもらえるのは非常にうれしい。
そんな喜びの気持ちをかみしめながら「今後も継続して、人前に出て話す機会をどんどん増やして続けていこう」、と決めたPaZooでした。
社内イベントはいいぞ
あくまでも私の価値観ですが、技術者としてプレゼン能力は必須だと感じています。そんな中で得た今回の機会は私にとって非常に大きなチャンスとなりました。
今回得た経験では、「分かりやすいプレゼン資料づくりのスキル」や「人に分かりやすく伝える技術」を身につけることができたように感じています。
もちろん今後も継続して続けていきます。(スキルは一朝一夕で身につくものではありませんからね!)
「人前で話すことに慣れていない!」や「現場でプレゼン資料作ることなんてないし…」という方。ぜひ社内イベントで発表しましょう。
技術者界隈では様々なイベントがありますが、まずは身内から話すと経験を積むことが出来てレベルアップにもつながりますよ。
こんないいイベントを作ってくれたまてぃーセンパイ、運営の方、本当に心から感謝いたします。ありがとうございました!
まてぃーセンパイの記事は以下のリンクからどうぞ!
ここまで読んでくださり、ありがとうございました!!
【ER図】リレーションシップについて勉強してみた。
皆さんこんばんは。管理人のPaZooです。
もう年の瀬ですね、早いものです。(毎年言ってる気がします)
さて、今回も時間差なAdvent Calendar ということで。
以前当ブログでご紹介した『ER図リレーションシップ』について、より勉強してみようということでまとめてみました。
最後まで読んでくださるとうれしいです^^
ER図のおさらい
ER図とは、皆さんもご存じのとおり 「E=エンティティ(実体)」「R=リレーションシップ(関連)」を用いたデータモデル図です。
エンティティがテーブルを、リレーションシップが関連性を示しています。
詳しくはこちらの記事でもご紹介しているので、興味がある方はぜひご覧ください!
今日のメイン!リレーションシップについて
「リレーションシップ」は関連という意味を持つよ、とお伝えしました。
より詳しく説明をしますと参照整合性制約のことを表します。
ER図では関係性のあるエンティティ同士で、条件に合った線を引いていくことで表現することができます。
書き方としては、以下の三種類を使い分けて設計していくことになります。
依存リレーションシップ
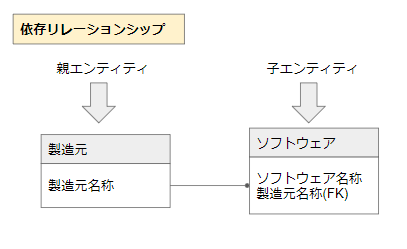
子テーブルの存在が親テーブルに依存している場合に、依存リレーションシップで表現されます。
ここで言いますと、製造元テーブルが親でソフトウェアテーブルが子です。
製造元テーブルにデータが存在して、初めてソフトウェアテーブルが成り立ちます。
その証拠に、子テーブルの主キーは親テーブルの主キーであることが分かります。
親なくして子の存在はありえないので、分かりやすいかと思います。
非依存リレーションシップ

子テーブルの存在が親テーブルに依存しない場合に、非依存リレーションシップで表現されます。
ここでいう親は顧客マスタテーブル、子は製造元テーブルにあたります。製造元テーブルでは、顧客マスタテーブルが保持しているデータを必要とせず存在することができます。
多対多リレーションシップ
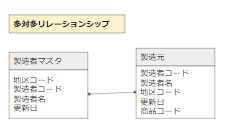
最後は、少し特殊な多対多リレーションシップです。
例えば、製造者マスタと製造元マスタが多対多の関係になります。
しかし、ここで注意点。
ER図の論理モデルでは表現することができますが、物理モデルにこのまま反映することができないので中間テーブルを用意して1対多として表現をします。

中間テーブルを新たに作成することで、多対多リレーションシップを表現することが可能となります。
【GAS】特定列の文字を指定文字に一括変換したいときの小ネタ【スプレッドシート】
おはやうございます、管理人のPaZooです。
Advent Calendar4日目の記事にしては小ネタのような気もしますが、まあよかろう。。
さて、今回仕入れたネタは「GAS」です。
タイトルにもある通り、「GASで特定列の文字を指定文字に一括変換したい!」という時に使えます!
管理人は、現場でスプレッドシートからCSVへ変換したいときに文字列にエスケープ文字「\r\n」・「\n」・「\r」が含まれている場合に空白文字に削除したかったので今回の実装を行いました。
スプレッドシート

GASソースコード
function myFunction() {//元データ取得var SSCopyForm = SpreadsheetApp.openById("***SpreadsheetId***");var SSCopyFromSheetsName = SSCopyForm.getSheetByName("シート名をここに記載");
//元データの最終行var LastRow = SSCopyFromSheetsName.getLastRow(); //最終行を取得var LastColumn = SSCopyFromSheetsName.getLastColumn(); //最終列を取得
//元データの取得した最終列、最終行までに入力された値を取得するvar CopyValue = SSCopyFromSheetsName.getRange(1,1,LastRow,10).getValues();
//貼り付け先のスプレッドシートのIDを指定してシート名を指定するvar SSCopyTo = SpreadsheetApp.openById("***SpreadsheetId***");var SSCopyToSheetsName = SSCopyTo.getSheetByName("シート名をここに記載");
//シートクリアSSCopyToSheetsName.clear();
//コピーした値を貼り付けるSSCopyToSheetsName.getRange(1,1,LastRow,10).setValues(CopyValue);
//貼り付けた値から削除対象文字を検索SSCopyToSheetsName.getRange("I2:I"+SSCopyToSheetsName.getLastRow()) //I列を選択.createTextFinder('\r\n|\r|\n') //対象の改行コードを指定.replaceAllWith("");}
解説
①コピー元シートの情報を取得
//元データ取得var SSCopyForm = SpreadsheetApp.openById("***SpreadsheetId***");var SSCopyFromSheetsName = SSCopyForm.getSheetByName("シート名をここに記載");
//元データの最終行var LastRow = SSCopyFromSheetsName.getLastRow(); //最終行を取得var LastColumn = SSCopyFromSheetsName.getLastColumn(); //最終列を取得
//元データの取得した最終列、最終行までに入力された値を取得するvar CopyValue = SSCopyFromSheetsName.getRange(1,1,LastRow,10).getValues();
今回の実装では、「コピー元シートをコピー先シートに複製してから、改行コードを消してほしい」という要望が挙がっていたので上のコードではコピー元データを取得しています。
②コピー先シートの情報を取得し、コピー元シートの情報を貼り付ける
//貼り付け先のスプレッドシートのIDを指定してシート名を指定するvar SSCopyTo = SpreadsheetApp.openById("***SpreadsheetId***");var SSCopyToSheetsName = SSCopyTo.getSheetByName("シート名をここに記載");
//シートクリアSSCopyToSheetsName.clear();
//コピーした値を貼り付けるSSCopyToSheetsName.getRange(1,1,LastRow,10).setValues(CopyValue);
コピー先シートのシートクリアを行い、コピー元シート情報の値をコピー先シートに貼り付けます。
③貼り付けされたコピー先シートから削除対象文字を検索して空白文字に一括置換
//貼り付けた値から削除対象文字を検索SSCopyToSheetsName.getRange("I2:I"+SSCopyToSheetsName.getLastRow()) //I列を選択.createTextFinder('\r\n|\r|\n') //対象の改行コードを指定.replaceAllWith("");}
ここで、貼り付けされたコピー先シートから削除対象文字を検索するため
「createTextFinder() 」メソッドで削除対象文字の「'\r\n|\r|\n'」を指定。
そのあとに、正規表現を使うようにtrueで定義して当該文字列に対して置換(今回は削除する)を行うよう指定してます。
短いですが、今回はここまで!
お役に立てれば幸いです!
はてな記法が使えなくてソースコードを引用で表現してます、すみません!
近いうち修正いれます!
駆け出してても駆け出そうとしてるエンジニアにも是非覚えてほしい『ER図』
こんにちは。管理人のPaZooです。
最近、めっきり寒くなりました。とうとう冬ですわ。
久しぶりにブログを更新しました。本当にいつぶりなのかもう記憶にもございませんです。
しかもAdvent Calendar1日目に、ER図についてのネタを持ってくるという…
うん、まあいいでしょ。うんうん。誰も怒らんし。
さて、今回のネタは「ER図」についてです。
私が参画している現場ではER図に触れる機会は全くと言っていいほどありません。
しかし、いざ現場で開発をやるうえでは知っておくべき知識のひとつであることは間違いないです。
今回は、私がざっくり「ER図」について学んだことを整理するためにまとめた記事です。
ER図の書き方や作成ツール、ER図から物理データベースを構築する方法はまた別の機会にご紹介したいと思います。
ER図とは
「ER図(英:entity relationship diagram)」とは、データベース設計における代表的な設計図のようなものです。
ER図はDOA(データ中心アプローチ)の技法です。
DOA(データ中心アプローチ)とは何かといいますと、システムの扱うデータの構造や関係を定義しそれに合わせて処理や手順の流れを決めていく方式のことを指します。
作成したER図は、そのまま物理データベース上に変換できることからデータベース設計手法におけるスタンダードなものとなっています。
ER図を書くメリット
エンジニアの中には、「データベース設計はテーブル設計書だけで作る」という方もいたり「設計を行わずにデータベースを構築する」という方もいると思います。
しかし、ER図を書くメリットとして「運用・保守フェーズで役立つ」ことを挙げさせていただきます。
システムは一度構築すれば終わり、というわけにはいきません。長い間稼働しながら改修を繰り返していきます。
ER図を整理することで、システム全体の構成が把握できますし、かつ品質の高いプログラムを製造することが可能です。
また、テーブル数が多くなれば設計ミスやプログラマが仕様を理解できないリスクが増大し不具合や後戻りのコストが発生してしまいます。
ER図を知っておくことで設計者以外でも設計内容を把握し、仕様変更などの改修に素早く対応できるようにしておきたいですね。
ER図の種類
ER図には、概念データモデル、論理データモデル、物理データモデルの3種類があります。

ER図の説明
ここでちょっとだけ寄り道します。
ER図を構成するために必要な「エンティティ」と「リレーションシップ」の役割について説明します。
エンティティ
エンティティとは、情報の対象となる物を概念としてモデル化したものです。
エンティティは、いくつかの属性(項目)を持っておりそれぞれの属性にはデータ制約(ユニーク制約や参照制約など)が定義されることがあります。
エンティティ内の属性に値が入ったものを「インスタンス」と呼びます。
エンティティは「概念」、インスタンスは「実体」と考えると覚えやすいかと思います。

リレーションシップ
リレーションシップは、業務上発生するエンティティ間の結びつきのことを指します。
二つのエンティティに含まれる属性の間で、何らかの参照関係が存在すると両エンティティはリレーションシップで結ばれるという感じです。
リレーションシップでつながれたエンティティ間は属性情報を並べて表現することができます。分かりにくい表現なので、下の図で説明をします。

「担当」エンティティが「社員」エンティティと「顧客」エンティティをつないでますね。
先ほど、上で申し上げた「エンティティ間の結びつき」というのが表現されています。このように、リレーションシップを使うことで、各テーブルをつないだデータベースを作ることができます。
リレーションシップには、今回の例で挙げた「1対1」だけでなく、「1対多」や「多対多」などありますので別の機会に詳しくお話しできればと思います。
概念データモデルと論理・物理データモデルの違い
さて、ここから概念データモデルの話に戻ります。
概念データモデルは、オブジェクトをシンボル化することで大まかに分類したものですが、論理・物理データモデルはデータベースに情報を追加するために必要なプロセスなどの詳細を表します。
概念データモデルでは、それぞれのエンティティを抽出したらエンティティ同士にリレーションシップを定義するので、トップダウンのモデリングによって作成されます。

対して、論理データモデルでは具体的な属性を付与したりリレーションシップを修正したりして概念データモデルよりもさらに詳細化したものです。
概念データモデルがトップダウンと表現されることに対して、ボトムアップのモデリングによって作成されます。

論理データモデルを作成したら、RDBに実装ができるように物理データモデルに落とし込んでいきます。
具体的には、属性のデータ型を定義したり、リレーションシップを基に属性の値に制約を設定したりします。
このように、ER図では段階的に考えながらデータベース設計ができることが特長となっています。
まとめ
今回は概念データモデルとER図についてお話させていただきました。
難しいかと思われた方もいるかと思いますが、理解してしまえば地理の地図のような感覚で見ることができます。(例えが特殊ですが)
これからもER図について学んだことをブログに書いていきますので、興味がある方は見てくださると励みになります。
【例外処理設計】あなたがエラーを見つめている時、エラーもまたあなたを見つめているのだ。
「どないやねん」とつっこみが聞こえてきそうです。皆さんこんにちは。管理人のPaZooです。
ALH Advent Calender 2日目 です!ALH Advent Calendar 2020 2度目の参戦。
(ちなみに、去年も2日目に書いてました。)
これもどこからかコピペしたような文章ですが、うちの会社の人(@supreme0110) が思い立ったが吉日のごとく「今年もやるぉーーーい!!!」という物凄い熱量で呼びかけていたので、またまた流れに身を任せて参加してみました。
今年はお声かけいただいてから翌日に記事を書きました。えらい。
去年は仕事に追われており、『明日やろーっと』が続いていたようですが今年はきちんと計画立ててやることができてます。えらいぞ。
さて、今回はシステムに携わる人なら避けては通れぬ道『エラー・例外処理設計』についてつれづれなるままに書いていこうかと思います。
本題:エラー処理・例外処理設計、これ大事。
エラー処理・例外処理設計とは
システムに携わる方なら耳にしたことがあるかもしれませんね。
個人的な理解として、エラー処理設計は想定内のエラーが発生したときに要件に沿った内容でエラー対応の処理を行うもの、例外処理は、想定外のエラーが発生したときに要件に沿った内容でエラー対応の処理を行うものだと考えています。
Javaをはじめとするオブジェクト指向言語では、「例外」という考えがあります。
例外が発生するパターンとして、正常な処理を妨げることが起こると「例外」を発生させるという処理を行います。
ちなみに皆さんは「エラー」と「例外」は同じように扱っていますか?
ソフトウェアの現場における「例外」に対する利用ケースはどうでしょうか。想定されているケースについても「例外処理」が使われているように感じます。
業務内容によっては、例外処理が実行された時点で処理を止めるものもありますし処理を継続させる必要があるものもあります。
この機会に、皆さんの現場では「例外」がどのような定義なのか、どのような処理を行うのかを見てみてはいかがでしょうか。
さて、話が逸れてしまったのでいったん本題に戻ります。
どうして例外処理設計が大事なのか。答えはいたってシンプル。
エラー処理・例外処理設計がされていないと、プログラム実行中にエラーが発生すると意図しないデータが保存されたり異常終了してしまう事態を招いてしまいます。
さらに、エラー処理・例外処理設計を行っていなければプログラムに適切な処理を実装していない場合、エラーが発生したり障害が起こったりするとエラーの原因を迅速に究明できず時間がかかってしまいます。
エラー処理・例外処理設計を行っていればデータの整合性を取ることができますし、エラー調査もしやすいという良いことずくめなのです!
特にアプリケーション開発を行っている場合は、適切なエラー処理・例外処理設計をすることは非常に重要なポイントとなってきますので必ずチェックしておきましょう。
例外(エラー) 処理設計の基本手順
ここでは、基本構造を設計する順番をご紹介していきます。
「エラー設計・例外処理設計ってどうやって考えたらいいの?」と思われるかと思います。以前の私もそう思っていました。。
まずは「システム基本構造」でエラーが発生しない場合を考えましょう。
いわゆる「正常系」のフローですね。そしてその次に、代表的なエラーを洗い出し、エラー別の大まかな対処方法を検討していきます。もちろん内容によってはシステム基本構造を変更せざるを得ないかもしれません。
両者を洗い出した段階で、矛盾する点が表れてくるかと思うのでそこから妥協点を見つけていくような検討方法があります。
システム全体で検討する必要がありますので、できるだけ早い段階でエラー処理設計を行うことが重要です。
エラー処理・例外処理基本設計 順序
- 考えられるエラーを洗い出す
- 洗い出したエラーを分類する
- 分類したエラーごとに重要度を評価する
- 分類したエラーごとに対処レベルを決める
- システム側で対処するエラーの処理方法を定める
- 必要に応じて、エラー対処に共通のクラスや処理を設計する
- 定めた処理方法に合わせて、個別のエラー処理を設計する
エラーを分類し、タイプごとに対処方法を検討しますので統一された対処が可能となります。
また、エラー処理に関しては共通のクラスや処理を使用できる場合もあるため無駄のないシステムを構成しやすいです。
例外(エラー) の種類
例外処理と一言で表していますが、立場・視点により意味合いは異なってきます。その中でも大きく分けて3つの分類のエラーを見ていきましょう。

軽く列挙するだけでも、これだけの数が挙がるんです。
もしもエラー処理設計を検討していない場合はどうなってしまうか…考えただけでも恐ろしいですね。エラー処理設計が如何に大切かお分かりいただけるかと思います。
例外(エラー) の種類ごとに対処を検討する
エラーの種類によっては、業務に多大な影響を与えてしまうかもしれません。ですので、分類したエラーは分類ごとに対処方法や重要度を検討しましょう。
どんな分類に分けるかといいますと、下記の内容を参考にしながら業務要件レベルで立てつけたほうがよいかと思います。
エラーの種類ごとに明らかにすべき項目
・発生時の損害の大きさ(業務停止や復旧時間など)
・エラーの発生頻度
・エラー処理の大まかな内容
業務要件レベルでシステムを理解したうえで、エラー設計・例外処理設計を行うことが良いシステムに近づけるのではないでしょうか。
おわりに
今回はエラー設計・例外処理設計について紹介してみましたが、いかがでしたか?
ここで最後にひとつだけ。
システムを構成するうえで必ずぶち当たる「エラー処理・例外処理設計」は、誰のためにあるのでしょうか。
個人的な考えですが、私は「システムを使うユーザへの情報伝達・再操作」こそエラー処理・例外処理設計の目的だと思っています。
一言で「エラー」と言っても、その起因を考え、処理を止めずにユーザへ情報を届けること。それが「エラー処理・例外処理」では大事なのではないでしょうか。
この辺のお話は、人それぞれ考え方がありますし、エラー・例外の定義をどのように扱っているかにもよるので一概には言えません。あくまでも管理人個人の意見だとあらかじめご了承ください。
それでは、また次回お会いしましょう!
LANケーブルでインターネット速度改善!
皆さんこんにちは、管理人のPaZooです。
私はオンラインゲームをするのでネット速度はかなり重要です。
今よりも速度を出すために色々調べてみていると「LANケーブル」にたどり着いたので、今回はLANケーブルについて調べた内容を備忘録のために記事にしました!
LANケーブルとは
LANケーブルの重要性についてあまり意識されていない方もいらっしゃるかと思います。
実はLANケーブルって、とっても重要な役割を持っているんです!!
LANケーブルとは、優先でインターネット接続をするために必要なものです。
私はPS4でオンラインゲームをするのでLANケーブルが絶対必要です。
一見同じように見えるのですが、製品によってカテゴリ(規格)はもちろん違いますが、素材や形状などによっても性能が変わってきます!
LANケーブルには「CAT5」のように数字がついていて、この数字が大きいほど性能が高いので高速通信回線に対応可能となっています。
カテゴリ(規格)によってどんな違いが出るのか
Gbps(ギガビット)
Gbps(ギガビット)とは、データを通信する単位です。
数字が大きいほど、大きな容量を短時間で送ることが可能。
MHz(メガヘルツ)
MHz(メガヘルツ)は伝送帯域で、データを送ることができる周波数の幅を表しています。
数字が大きいほど、送るデータの量が増えます。
LANケーブルの選び方
快適なゲームやPC環境を整えたいなら「CAT7」以上!
CAT7は通信速度10Gbps、帯域は600MHzに対応しており通信ノイズの耐性が高いです。
そのため、通信速度が速く伝送帯域が高いので高速通信が可能。
オンラインゲームやインターネット通信速度に不満を感じている方はLANケーブルをCAT7にしてみましょう!
速度を重視しないなら「CAT6」でよいです。
CAT6は、通信速度1Gbpsで伝送帯域が250MHzに対応しています。
一般的な光回線の契約は1Gbpsなので、速度を重視せずにインターネットサーフィンや動画配信サイトを楽しむのであればCAT6にすると快適に感じますよ。
ちなみに、CAT6とCAT7の中間性能のLANケーブルとして「CAT6A」もありますよ。
形状の違い
LANケーブルには、「スタンダード」「極細」「フラット」「リール」という形状があります。それぞれの特徴をまとめてみました。
スタンダード

スタンダードタイプのLANケーブルは、比較的太い導線が使われています。
ケーブルの断面が丸くなっており、ほかの形状と比べてみるとケーブルが曲がりにくいため長い距離の配線に適しています。
伝送するスピードや安定性に優れているため、通信ノイズの影響を受けづらいのが特徴です。
極細

極細タイプのLANケーブルは、スタンダードタイプよりも細い導線でケーブル自体が比較的柔らかい素材のため、曲げやすく取り回しが良いところが特徴。
見た目も細いため、配線周りもすっきりします。
フラット

フラットタイプのLANケーブルは、ケーブルの形状が平たくて薄いことが特徴です。
スタンダードタイプと比較すると強度は劣るため、無理に引っ張ったりしないよう気を付けてください。
リール

リールタイプのLANケーブルは、使用しないときに巻き取ってコンパクトにできるという特徴があります。
非常に便利ですね!
LANケーブルの長さ
LANケーブルには様々な長さがあり、利用用途により必要になる長さが変わってくるので購入前に測っておくことをおすすめします。
また、ケーブルの導線には「単線」と「より線」の2種類が存在します。
単線:硬く、通信ノイズを受けにくい。
より線:柔らかく取り回ししやすい。
ノイズが発生しやすい20cm以上の距離では単線を、20㎝以下の距離でケーブルを曲げる場合はより線がオススメですよ!
まとめ
管理人は正直、違いが分からずに「とりあえず買っとけ!」くらいの認識でしたが性能が全く違うことにびっくりしてしまいました(笑)
通信速度が遅いと感じる方は、自分が契約しているインターネット回線の通信速度をチェックして目的に応じたLANケーブルを購入しましょう!
参考になれば幸いです。
ではまた!